 2018, Vol. 34
2018, Vol. 34 



要将自然语言交给机器学习中的算法来处理, 通常需要将语言数学化, 词向量就是将语言中的词进行数学化的一种方式。词向量将某种语言中的每一个词映射成一个固定长度的短向量, 将所有这些向量放在一起形成一个词向量空间, 而每一词向量则为该空间中的一个点, 在这个空间上引入“距离”, 则可以根据词之间的距离来判断它们之间的语义、语法上的相似性。词向量具有良好的语义特性, 可用于改善和简化许多自然语言信息处理应用, 并且词向量的质量影响自然语言信息处理应用的性能。因此, 针对蒙古语词性标注、命名实体识别、短语识别、机器翻译方面的应用需求训练蒙古语词向量, 研究词向量的评测具有重要的研究意义。词语作为连续向量的表示具有悠久的历史。已有许多学者用不同模型训练了词向量, 比较经典的模型有神经网络语言模型(NNLM)[1]、双对数线性语言模型(LBL)[2]、循环神经网络语言模型(RNNLM)[3]、连续词袋模型(CBOW)和Skip-gram模型[4]等。另外, Mikolov等[5]还提出了Skip-gram模型的几个扩展, 即Hierarchical Softmax算法、负采样算法和欠采样技术, 从而提高了词向量的质量和训练速度。针对形态丰富的语言, Bojanowski等[6]提出了一种基于Skip-gram模型的新方法。此外, 词向量可用于改善和简化许多NLP应用[7-8]。
词向量的评价方法有两种:一个是把词向量融入到现有系统中, 看能否提升现有系统[9]; 另一个是从语言学的角度分析词向量, 比如相似度。研究者发现相似的词不仅彼此接近, 而且这个词具有多重相似度。这在早期的变形语言中已被观察到, 例如, 英语名词可以有多个单词结尾, 如果在原始向量空间的子空间中搜索类似的单词, 可以找到具有相似结尾的单词[10-11]。蒙古语是黏着性语言, 其形态丰富, 并存在许多词根相同的名词和动词的变形形式, 这些形式表示相似的概念。比如动词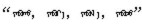
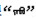
词向量具有良好的语义特性, 可以通过加减法操作来对应某种语义语法关系, 并通过语义语法相似性来评价词向量。比如判断与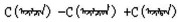
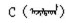
在大量数据上训练高维词向量时, 所得到的向量可以回答诸如城市和它所属的国家之间的单词之间的微妙语义关系, 例如, 巴黎是法国的, 柏林是德国的。根据这种现象本研究建立了两种蒙古语语义关系集:首都-国家关系和男-女关系。每个类别的两个实例如表 1所示, 相同类别的两个单词对连在一起构成一个语义问题, 共有100个语义问题。本测试集中只包含一个词构成的单词, 不包含多单词实体(如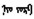
| 表 1 语义测试集中的两种语义关系实例 Table 1 Examples of two types of semantic questions in Semantic test set |
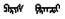
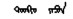

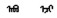
蒙古语名词有格、数、领属等范畴的形态变化。蒙古语的格是通过名词后面缀接格附加成分来表示, 例如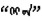
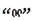
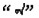
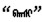
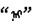

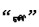
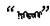
本研究结合蒙古语法特征建立了关于蒙古语名词格、复数、数词和代词的4种语法关系集。每个类别的两个实例如表 2所示, 相同类别的两个单词对连在一起构成一个语法问题, 共有544个语法问题。
| 表 2 语法关系测试集中4种类型语法问题实例 Table 2 Examples of four types of syntactic questions in Syntactic test set |
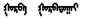


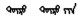
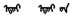
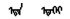
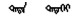
使用类比方式在建立的语义语法测试集上评测蒙古语词向量质量。具体操作方法:设语义语法测试集中每个问题的4个词依次对应a、b、c、d。已知a之于b犹如c之于d。先给出a、b、c, 再看C(a)-C(b)+C(c)最接近的词是否是C(d)。如果计算出来的向量与测试集中的词d完全相同, 则认为是正确答案。本研究评估所有问题类型的总体准确性, 并分别对语义、语法问题进行评估。
2 蒙古语词向量模型架构词向量可以使用NNLM、RNNLM、LBL等不同模型架构来学习, 这些架构的计算复杂度比CBOW和Skip-gram模型要高出许多, 因此本研究采用CBOW和Skip-gram模型训练蒙古词向量, 并采用Hierarchical Softmax加速策略。
在CBOW模型和Skip-gram模型中, 目标词wt是一个词串中间的词而不是最后一个词, 其拥有的上下文为前后m个词, m为模型窗口的大小。
CBOW模型是根据上下文预测目标语言的概率来优化词向量的。蒙古语n-gram语言模型中4元模型的效果最好, 因此, 本研究在窗口为3~6的情况下训练蒙古词向量, 训练语料为27万蒙古文句子, 词向量维度为300, 并用建立的语义语法测试集评测词向量。从表 3可以看出, 窗口为4的情况, 下词向量质量最好, 所以用于训练蒙古语词向量的CBOW模型的窗口大小为4, 目标词的上下文为该词前后的4个词。模型架构如图 1a所示。举个例子, 假如给定一个词的前面4个词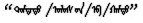
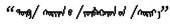
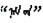
| 表 3 不同窗口下CBOW模型的性能 Table 3 Performance of CBOW model under different window size |

|
图 1 蒙古语词向量模型架构 Fig.1 Mongolian word vectors model architecture |
Skip-gram模型根据当前词预测上下文的概率来优化词向量, 同样本研究在窗口为3~8的情况下分别训练蒙古词向量, 训练语料为27万蒙古文句子, 词向量维度为300, 并用建立的语义语法测试集评测词向量。从表 4可以看出, 窗口为5的情况下, 词向量质量最好。
| 表 4 不同窗口下Skip-gram模型的性能 Table 4 Performance of Skip-gram model under different window size |
所以用于训练蒙古语词向量的Skip-gram模型的窗口大小为5, 根据当前词预测词前后5个词。模型架构如图 1b所示。
3 实例验证使用上述CBOW模型和Skip-gram模型训练蒙古语词向量。训练语料采用CWMT2015的蒙古语训练语料和内蒙古大学100万词级的《现代蒙古文数据库》。上述两种语料是蒙古文拉丁转写形式, 因此训练之前, 先将单词与标点符号进行分割。
训练完成后, 使用类比方式在建立的语义语法测试集上评测蒙古语词向量质量。表 5是在不同大小的训练数据和不同维度下, 用Skip-gram模型训练词向量的结果。由表 5可以看出, 在某些方面, 添加维度或添加训练数据可以提高词向量质量。
| 表 5 Skip-gram架构在蒙古语语义语法关系测试集上的总体准确性 Table 5 The overall accuracy of Skip-gram architecture in Mongolian semantic-syntactic relationship test set |
为了比较两种模型架构, 本研究在规模为23 M的训练语料上分别用CBOW模型和Skip-gram模型训练词向量, 词向量维度为300。结果表明, 对于蒙古语而言, 词法和语义任务上Skip-gram模型优于CBOW模型(表 6)。
| 表 6 模型架构在语X语法测试集上的准确性比较 Table 6 The accuracy comparison of model architecture in semantic-syntactic test set |
综上所述, 蒙古语语义准确率总体比较低, 第一个原因是测试中忽略了同义词的概念, 比如, 就测试集中的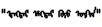

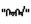
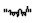
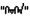
本研究分别使用CBOW模型和Skip-gram模型训练蒙古语词向量, 并在自己建立的语义和语法测试集上评测了词向量的质量。研究表明, 利用Skip-gram模型且窗口为5的情况下蒙古语词向量质量最好。随着词向量维度或训练数据的增大, 词向量质量有明显的提高。
蒙古语是个形态丰富的语言, 有着丰富的数、格、时、体、态等形态变化。这导致了蒙古语的词汇量庞大。词向量训练时使用固定大小的词汇表, 这使得罕见词语无法向量化。因此, 在后续工作中将研究基于子词单元(比如词素级、字符级)的词向量表示来提升形态丰富语言的性能。词向量训练好以后, 通常会作为各种神经网络结构的初始值, Word2vec模型是很浅层的神经网络, 词向量经预训练后做为其初始值, 通常可以提升任务上的效果。因此, 后续研究将会把训练好的词向量作为初始值, 运用到蒙汉机器翻译任务上, 以提升其翻译效果。
| [1] |
BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3: 1137-1155. |
| [2] |
MNIH A, HINTON G. Three new graphical models for statistical language modelling[C]. 24th Annual International Conference on Machine Learning (ICML), Corvallis, 2007.
|
| [3] |
MIKOLOV T. Statistical language models based on neural networks[D]. Lausanne: Brno University of Technology, 2012.
|
| [4] |
MIKOLOV T, YIH W, ZWEIG G. Linguistic regularities in continuous space word representations[C]. Proceedings of NAACL-HLT, 2013.
|
| [5] |
MIKOLOV T, SUTSKEVER I, CHEN K. Distributed representations of words and phrases and their compositionality[C]//BURGES C J C, BOTTOU L, WELLING M, et al(eds. ). Advances in neural information processing systems 26 (NIPS 2013). Nevada:[S.n.], 2013.
|
| [6] |
BOJANOWSKI P, GRAVE E, JOULIN A, et al. Enriching word vectors with subword information[Z]. Facebook AI Research, 2016.
|
| [7] |
COLLOBERT R, WESTON J, BOTTOU L. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12: 2493-2537. |
| [8] |
KIM Y. Convolutional neural networks for sentence classification[C]. Empirical Methods in Natural Language Processing.[S.l.], 2014.
|
| [9] |
TURIAN J, RATINOV L, BENGIO Y. Word represe-ntations: A simple and general method for semi-Supervised learning[C]. Proc Association for Computational Linguistics.[S.l.], 2010.
|
| [10] |
MIKOLOV T. Language modeling for speech recog-nition in Czech[D]. Lausanne: Brno University of Technology, 2007.
|
| [11] |
MIKOLOV T, KOPECKY, BURGET L, et al. Neural network based language models for highly inflective languages[C]. International Conference on Acoustics, Speech and Signal Processing.[S.l.], 2009.
|