 2018, Vol. 34
2018, Vol. 34 


2. 伊犁师范学院, 中国锡伯语言文化研究中心, 新疆伊宁 835000
2. China Xibo Language and Culture Research Center, Yili Normal College, Yili, Xinjiang, 835000, China
传统蒙古文、托忒文、锡伯文和满文具有相似性, 都是一个字母具有独立、词首、词中、词尾4类不同形态, 且字母的每种形态具有零到多个规范的(通常认为是被列入字母表中的)字符形式。除此之外, 一些字母在某些特定上下文情况下还有其他的形变字符形式, 是世界上最为复杂黏着连写的字符系统。例如锡伯文元音u的字符有1种独立形式、1种词首形式、3种词中形式和5种词尾形式。
蒙古文信息技术国家标准工作组发布的国家推荐标准GB/T 26226-2010[1]中给出的编码字符集是以传统蒙古文为基础, 在一个字母的多个字符形式中择其一个, 并指定一个计算机编码码位, 这个字符被称为对应字母的名义字符。其他的几种文字则以托忒文、锡伯文、满文和阿礼噶礼字(蒙古文阿礼噶礼和满文阿礼噶礼本质上是蒙古文和满文为梵文注音而创制的注音符号, 本身并非一种文字)的顺序依次认同或补充新的名义字符, 也就是如果名义字符中已经存在本语种对应字母的名义字符, 则认同该名义字符为本语种文字的名义字符, 否则就补充一个新的名义字符。一个字母的多个字符形式, 除了名义字符外, 其他字符形式则以变形显现形式表示。
名义字符系统虽然减小了编码字符集的规模, 却带来了诸多的其他问题, 其中最典型的有以下3个:
(1) 锡伯文和满文中有的字符与传统的蒙古文名义字符有相同的字符形式, 却不能认同。例如:蒙古文元音i的名义字符为独立形式字符“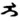
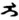
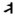
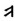
这样的情况在GB/T 26226-2010[1]中还有很多。究其原因, 是不同语种字符的拼写规律存在差异, 用同一个名义字符, 难以实现字符在不同上下文的各种变化, 也就是存在名义字符在不同语种中变形显现的冲突问题。
(2) 由于一个名义字符需要对应太多的变形显现字符, 使名义字符与变形显现字符对应的逻辑关系变得非常复杂, 产生了选择冲突, 致使某些字母无法简单地以字母在单词中的位置自动来确定采用何种变形显现字符。为了解决这个问题, GB/T 26226-2010[1]不得不采用人工干预的方式, 人为输入控制符来选择合适的字符形式。
这套标准中使用的控制符有7个:GB/T 26226-2010[1]的名义字符表里有4个, 即自由变形选择符1(FVS1:180B)、自由变形选择符2(FVS2:180C)、自由变形选择符3(FVS3:180D)和蒙古文元音间隔符(MVS:180E), 此外还使用了窄无间断空格(NNBSP:202F)、零宽度连接符(ZWJ:200D)和零宽度禁连接符(ZWNJ:200C)。
表 1就是GB/T 26226—2010[1]给出的使用控制符的典型示例。控制符的使用, 不仅难以记忆、容易遗忘, 更重要的是会给普通用户造成疑虑和困惑, 尤其是以改变用户操作习惯为代价的。

举个简单的例子:
例1 人们在编辑文本时, 无论是汉文还是其他语言的文字, 经常会有这样的情况, 就是为了某种目的, 会用空格将单词中的每个字或者每个字母分开。例如:“中国国家标准”→ “中国国家标准”, “Standard”→“S t a n d a r d”。又比如, 拼音文字在文化教育中经常会拆解组合, 如图 1所示。

|
图 1 锡伯文单词alin的拆解和组合 Fig.1 The split and combination of the Sibe word alin |
图 2给出了4组单词直接插入空格后的拆解情况对比:第1组是人们预期的效果, 后面3组是使用GB/T 26226-2010[1]标准的单词拆解情况。编号为2的是微软字体Mongolian Baiti, 编号为3的是易文通字体SMBT1, 编号为4的是蒙科立字体Menk Qagan Tig。

|
图 2 4组单词插入空格后的效果比较 Fig.2 A comparison of 4 word letters inserted into spaces |
后面3组字体出现这种情况的原因是字符采用的是名义字符编码, 在单词中插入空格后, 名义字符失去了变形的依据, 则只能以名义字符默认的字符形式显示。这3种字体如果想要达到预期的效果, 除了插入3个空格外, 还必须分别插入6个控制符。
采用名义字符编码, 不仅会出现插入空格这样的问题, 在字符的查找、搜索、替换这样普通的文本操作上也会引起人们的困惑和疑虑。
(3) GB/T 26226-2010[1]中的名义字符集首先是以传统蒙古文的某种辞典序排列的, 其他语种则以认同、补充的方式附加在其后面。对于传统蒙古文这是有序的, 然而对于其他文种而言则是无序的。虽然国际标准中并不要求字符的有序性, 但也并不排斥字符的有序序列。如果传统蒙古文、托忒文、锡伯文、满文和阿礼噶礼的字符都像拉丁字母的字符那样是一个统一的有序序列, 那么对这些文种的信息处理和应用将极为有利。
鉴于上述问题, 下面将给出一种针对传统蒙古文、托忒文、锡伯文和满文的、有序的、基于规范字符的多语种统一字符编码方案。
1 几个术语的定义 1.1 GB/T 26226-2010[1]的定义名义形式(Nominal Form), 即名义字符。GB/T 26226-2010[1]中给出了其定义:蒙古文字母的主要形式。它适用于蒙古语的书面形式以及附加符号的表示、传输、交换、处理、存储、输入及显现。
变形显现形式(Presentation Form), 即变体显现字符。GB/T 26226-2010[1]中给出了其定义:一个字母的各个显现形式为该字母的名义形式或其他图形字符区的字符序列在特定上下文中的使用提供可选形式, 这种形式依赖于该字符相对于其他字符的位置。通常, 显现形式不用于替换本编码字符集中规定图形字符的名义形式。
自由变体选择符(Free Variation Selector)。一种组合用字符, 紧随于特定的名义字符之后, 用来区分在同一条件下的同一个名义字符的不同变体。
1.2 本方案的定义规范形式(Normalized Form), 即规范字符。规范形式是传统蒙古文、托忒文、锡伯文和满文等多个语种字母的基本表示形式。它包括字母的独立、词首、词中和词尾字符的基本形式。
变形显现形式(Presentation Form), 即变体显现字符。变形显现形式是字母规范形式在某些特殊上下文条件下与对应规范字符相似且有一定形变的变形显现字符形式。
1.3 关于定义的说明通常, 可以将规范形式看做是一个文种字母表中所有的字符形式(事实上这些字母表往往是不完备的)。规范字符包括了字母的各种基本形式, 这些基本形式都是常见的, 并且字符形态对于同一个字母而言多数具有较为明显的差异, 主要体现了字母在单词中不同位置时的差异性以及与不同上下文拼写时的差异性。例如锡伯文、满文的字母e, 其规范字符如表 2所示。
| 表 2 锡伯文、满文字母e的8种规范字符表示形式 Table 2 The eight normalized character representation of Sibe and Manchu letter e |
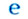




本方案的变形显现形式与规范形式的差异并不十分明显。例如: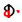
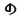
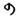

蒙古文、托忒文、锡伯文和满文都是纵向黏着连写的拼音文字, 字母的字形和功用(或者说是所用字符的目的)也有相似性。因此, 本方案的这几种文字的认同是以各文种规范字符的语音、字形和功用加以综合考虑的。例如:对于元音a, 几种文字都存在相应的规范字符, 可以将这几种文种a的规范字符整合在一起, 如表 3所示。
| 表 3 蒙古文、托忒文、锡伯文和满文元音a的规范字符 Table 3 The normalized characters of Mongolian, Todo, Sibe and Manchu vowel a |
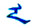
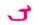

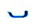
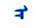
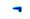
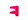

从表 3可以看出, a字母的第1种独立形式、词尾形式、词首形式和第1种词中形式是4种文字共同认同的; a字母的第2种独立形式和第2种词中形式是传统蒙古文和托忒文共同认同的, 第3种词中形式则只属于传统蒙古文。
2.2 多语种规范字符集的整合表 3给出了4个文种整合起来形成的一个字母a的各种字符形式的一个序列, 这个序列就是字母a的多文种规范字符集。采用同样的方式, 其他字母也可以形成各自字母的多文种规范字符集。所有字母的规范字符集按一定的顺序整合在一起, 就形成了一个多文种规范字符集, 每个字母的规范字符集则是整个多文种规范字符集的一个子集。
2.3 需要澄清的问题通过上述方式形成的规范字符集, 会产生多个字形相似甚至字形完全相同的规范字符。以锡伯文和满文为例, 元音字母a的第一词中形式、元音字母e的第二词中形式和辅音字母n用于收音的词中形式字形完全相同, 都以“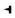
国际标准ISO/IEC 10646—2014[2]中6.3.2节关于图形字符有这样一段描述:“相同的图形字符不能分配一个以上的码点。在本编码字符集中存在形状相似的图形字符, 但他们用于不同的目的并具有不同的字符名称。”国际标准中又做了这样的举例:“本标准中规定的图形字符用它们的名称作为唯一的标识。这并不意味着这些图形符号成像的图形一定是不同的。图形字符相似的图形符号的例子有大写拉丁字母A, 希腊大写字母阿尔法和西里尔大写字母A。”同样都是A, 字形完全相同, 但它们分别是不同语种的字母符号, 他们用于不同的目的并具有不同的字符名称。因此, 在国际标准中虽然字形相同, 但他们分别有各自的编码。
规范字符中的3个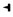

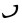
同理, 一个字母的多个不同形式, 只要是用于不同的目的并具有不同的字符名称, 也可以作为编码字符集的一个成员。比如拉丁字母的大写字母和小写字母都具有不同的字符编码; 又比如位于FB50~FBFF码位区间的阿拉伯文包含了字母的独立、词首、词中、词尾不同的形变字符形式; 又比如汉字“国”和“國”是同一个字的简体形式和繁体形式, 虽然字义相同, 但字形不同, 使用的目的也不同, 国际标准ISO/IEC 10646—2014[2]中分别指定在码位56FD和570B上。因此, 没有理由将蒙古文、托忒文、锡伯文和满文规范字符集中的, 除名义字符外的其他字符排斥在编码字符集之外。
2.4 阿礼噶礼字的问题蒙古文阿礼噶礼字和满文阿礼噶礼字是蒙古文和满文对梵文的注音符号[3-4]。梵文的语音比较丰富, 大多数情况下传统蒙古文和满文都可以用已有的字符进行注音, 但是, 仍然有一些语音无法标注, 因此传统蒙古文和满文针对这些语音又创制了一些新的注音符号, GB/T 26226—2010[1]中的阿礼噶礼就是这部分注音符号的名义字符。
这些阿礼噶礼字符除了针对特定的语音外, 从字符形式而言, 也有规范的独立、词首、词中、词尾的字符形式。因此, 也可以采用上面所述的方式建立相应的规范字符集。
3 规范字符集的顺序和编码 3.1 规范字符集子集字符的顺序规范字符集子集中字符的顺序就是一个字母的规范字符的顺序。这个顺序体现字符串比较时相同字母的不同字符之间的排序关系。这个问题已经有非常成熟的结论:一个字母的不同字符形式可以按以下任意一种方式排列:(1)独立形式, 词尾形式, 词首形式, 词中形式。(2)独立形式, 词首形式, 词尾形式, 词中形式。表 1就是按照方式(1)排列的, 对于不同文种, 由于认同的原因, 也不存在孰先孰后之分。
3.2 规范字符集字母子集的顺序字母子集的顺序体现的就是字母的顺序。目前, 我国拼音文字(包括注音符号)的顺序有以下3种:(1)拉丁字母顺序(a, b, c, ……), (2)汉语拼音注音符号顺序(b, p, m, f, ……), (3)文字传统顺序(如蒙古文、满文按12字头中字母出现的顺序)。
许多学者出于传承传统文化的意愿, 似乎更愿意采用传统顺序。但是, 无论是蒙古文12字头或者满文12字头, 都是以音节形式表现的, 虽然多数字母有一定的顺序, 仍然有不少字母没有给出确定的顺序, 从而出现了不同顺序的传统排序方式。例如蒙古文辞典的顺序就有17种之多[5], 满文辞书也有类似的情况。并且, 由于语种的不同, 元音辅音的数量不同, 其传统顺序的排序习惯也不尽相同, 因此, 要形成一个多语种统一的顺序, 传统顺序显然是不可取的。
最初不少汉文典籍中采用的就是汉语拼音顺序或其他注音符号顺序。传统蒙古文、托忒文、锡伯文、满文多语种字母排序按汉语拼音顺序也并非不可。但是随着计算机技术的应用以及国际化趋势, 现在的新版《新华字典》《汉语词典》等汉文字典词典也都采用了拉丁字母顺序排序。
因此, 规范字符集字母子集的顺序按照拉丁字母的顺序排序应该是一个理想的选择。至于传统蒙古文、托忒文、锡伯文、满文以及阿礼噶礼字母中一些用英文的26个字母无法对应而采用其他扩充拉丁字母形式表示的, 则需要国家相关机构组织相应的信息技术国家标准工作组以及有关专家共同协商解决。一旦这些拉丁字母形式确定之后, 字母的顺序按拉丁字母以及扩充的拉丁字母的固有顺序排列即可。
3.3 规范字符集的编码在规范字符集的基础上进行字符的编码, 可以采用两种方式:
(1) 按照规范字符集的字符给定的顺序编码。这需要相关组织和机构重新划定或扩充这几种文种的编码区间。如果是重新划定编码区间, 就能充分发挥规范字符集的优势, 如果仅是扩充编码区间, 原来1800~18AF码段的字符则需要重新规划, 调整字符的顺序。
(2) 原来1800~18AF码段的字符不做调整, 只在新的编码区间指定规范字符集中补充的其他字符的码位。这种方式会降低编码字符集的使用效率, 丧失在查询、搜索、排序方面的优势。
4 结束语采用本研究方案的规范字符集, 编码字符的数量有一定的增加。GB/T 26226—2010[1]中蒙古文、托忒文、锡伯文、满文和阿礼噶礼字的名义字符一共有123个(不包括数字和其他符号), 而规范字符初步统计大约为360~370个, 也就是说规范字符的数量仅比名义字符多不到250个。从数量上而言, 似乎是个缺点, 然而, 这个数量的增加并不十分明显, 带来的好处却是十分显著的。这一方案, 使文字处理过程更加符合用户的一般使用习惯, 在插入空格、查找、替换等操作上与拉丁文、中文的操作保持一致, 不再令用户困惑和疑虑。其次, 规范字符的使用使字符的形变逻辑变得简单, 因此无论是锡伯文还是满文, 都不再需要靠自由变体选择符来加以控制和改变, 传统蒙古文和其他文字也会大大减少控制符的使用。采用规范字符, 当然会使输入法的编程处理过程变得复杂得多, 然而, 这个难题面对的对象是软件编程人员, 对于普通用户而言, 则是文本处理过程更为简单方便。另外, 如果能按照前面方式(1)提出的规范字符的顺序进行编码, 则会大大提高文字信息的搜索、比较、排序的效率, 减少文字信息处理的成本。总而言之, 规范字符集的方案更有利于这几种文种的信息化建设的发展。
| [1] |
确精扎布, 陈壮, 何正安, 等. 信息技术蒙古文变形显现字符集和控制字符使用规则: GB/T 26226—2010[S]. 北京: 中国标准出版社, 2011. CHOIJINGJAB, CHEN Z, HE Z A, et al. Information technology —Mongolian presentation forms character set and use rules of controlling characters: GB/T 26226—2010[S]. Beijing: China Standard Press, 2011. |
| [2] |
ISO/IEC JTC1/SC2/WG2. Information technology—Universal coded character set (UCS): ISO/IEC 10646-2014[S].[S:l,s:n], 2014.
|
| [3] |
聂鸿音. 《同文韵统》中的梵字读音和汉语官话[J]. 满语研究, 2014(1): 5-10. NIE H Y. Sanskrit and Mandarin pronunciation in Tongwen Yuntong[J]. Manchu Studies, 2014(1): 5-10. |
| [4] |
同文韵统, 阿礼嘎礼.读咒法[M].清乾隆内府刻本.上海:上海涵芬楼影印, 民国十八年. TONGWEN Y T, ALIGALI.Read the mantra method[M].Photocopy of the Qing Qianlong inner palace.Shanghai:Shanghai Hanfeng Building, The 18th year of the Republic of China. |
| [5] |
米吉生. 蒙文字母表与蒙文辞书的音序排序[J]. 内蒙古师大学报:哲学社会科学版, 1982, 9(1): 17-19. MI J S. The alphabetical order of the Mongolian alphabet and the Mongolian dictionary[J]. Journal of Inner Mongolia Normal University:Philosophical & Social Science Edition, 1982, 9(1): 17-19. |