



2. 广西科学院《广西科学》编辑部, 广西南宁 530007;
3. 贺州学院经济与管理学院, 广西贺州 542899
2. The Editor Office of Guangxi Sciences, Guangxi Academy of Sciences, Nanning, Guangxi, 530007, China;
3. School of Economics and Management, Hezhou University, Hezhou, Guangxi, 542899, China
近年来,飞速发展的人工智能(Artificial Intelligence,AI)成为各学科发展的关键推动力,深度学习技术在AI领域中越来越重要。大语言模型(Large Language Model,LLM)是一种基于深度学习技术,以海量语料库为基础训练出的自然语言处理模型[1-2],如ChatGPT[3-5]、Claude和DeepSeek等,均在AI领域产生了重要影响。神经网络作为实现深度学习的基础,通常是“黑箱”模型,无法揭示模型背后的潜在原理,降低了用户对系统的信任度。因此,探究数据之间的因果关系成为解决这个“黑箱”问题的关键路径。
因果关系是指自变量导致因变量发生变化的关系。在统计学中,当两个随机变量X和Y在统计上相关时,可能存在以下3种情况:①X→Y;②Y→X;③∃Z使得Z→X和Z→Y,其中Z为混杂变量。推断数据中因果关系的过程被称为因果发现,又称贝叶斯网络学习。因果网络是一种采用基于因果贝叶斯网络理论的有向无环图(Directed Acyclic Graph,DAG)来表示变量之间因果关系的图模型。在因果网络中,节点表示随机变量,有向边表示因果关系及其方向。因果网络是对多变量进行因果关系推断的关键工具,用于因果关系可视化[6]。
基于观测数据的因果发现是一项具有挑战性的任务。现有的基于约束(Constraint-based)的因果发现算法易产生过多的冗余条件独立性测试,导致计算效率低。尽管无法完全避免所有冗余的条件独立性测试,但设计有效的分解策略可以尽可能减少冗余条件独立性测试,从而提高因果发现的效率。因此,本研究着眼于DAG的结构特性进行突破。DAG作为因果图模型的数学基础具有天然的模块化特性,本研究提出将图分割技术应用于因果分解,通过将复杂因果网络拆解为若干相对独立的子图模块,有效降低全局条件独立性测试的复杂度。在具体技术选择上,本研究采用K-means聚类进行因果分解。K-means聚类是一种经典的图分割技术,其分割效果好、泛化性强,能够适用于多种图结构[7]。
综上,本研究将K-means聚类方法与条件独立性测试结合,提出一种新的因果分解方法(Causal decomposition method based on K-means clustering,CDKM)。CDKM通过无监督聚类将全局因果网络学习转化为多个子因果网络学习任务,相比递归型基于约束的方法,CDKM无需进行高阶条件独立性测试划分簇,避免了高阶条件独立性测试的使用,并显著减少了冗余测试,从而在因果发现中实现了更高的效率和更低的时间复杂度,为高维因果发现提供了高效解决方案。
1 相关工作 1.1 因果发现算法基于约束的因果发现算法[8-11]利用条件独立性测试方法推断数据中的因果关系,进而构建因果网络。因此,条件独立性测试是基于约束的方法的核心部分,决定了其效率和精度。其中,Peter-Clark (PC)算法作为一种经典方法,其首先基于观测变量集构建一个全连接无向图(骨架),然后通过遍历式(条件)独立性测试对变量之间的边进行保留或删除,最后识别V-结构并通过一致性传播确定因果方向[8]。PC算法能够与不同的条件独立性测试方法结合进行因果发现,但由于需要遍历式地进行条件独立性测试,会产生大量冗余测试,导致计算时间成本极高。Inductive Causation (IC)算法[9]与PC算法的主要区别在于条件独立性测试和构建骨架的顺序。Fast Causal Inference (FCI)算法[10]进一步扩展了处理隐变量和选择偏差的能力。Really Fast Causal Inference (RFCI)算法[11]是FCI算法的变体,它在处理高维数据时更有效。
基于因果函数模型的算法[12-15]的原理是假设因变量y和自变量x之间存在某种函数关系,进而推断因果关系。比如,若y=f(x)+εy,x=g(y)+εx,噪声项εy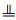
面对基于约束的算法会产生大量冗余的条件独立性测试的问题以及基于因果函数模型在高维因果网络上效果差的挑战,混合因果发现算法[16-18]被提出。这种算法主要混合上述算法进行因果发现。Scalable cAusation Discovery Algorithm (SADA)[16]通过在变量之间的稀疏概率图模型上找到切割点,将变量分成子集,也就是将原始的因果发现问题分解为多个子问题,然后在子问题上运行主流因果发现算法,如LiNGAM等,再通过组合所有子结果来重建完整的因果网络。SADA减少了一定的冗余条件独立性测试,提高了因果发现的效率和准确性,但因其需要通过穷举法最小化分离集,这意味着仍需要大量的条件独立性测试,导致计算时间复杂度较高。Causality Partitioning (CAPA)算法[17]通过设计递归分解方法降低冗余条件独立性测试,同时采用基于回归的条件独立性测试处理线性非高斯加性噪声模型,CAPA算法能够显著减少不必要的条件独立性测试并有效区分Markov等价类。尽管CAPA算法比SADA更有效,但它在分解中需要进行高阶条件独立性测试,这影响了CAPA算法在高维因果发现任务中的效率和准确性。为了避免在分解中进行高阶条件独立性测试,Causal Decomposition based on Spectral Clustering (CDSC)算法[18]通过构建原始变量集的Laplacian矩阵,利用谱聚类将原始变量集分解为多个子集,然后恢复每个子集的因果网络,最终合并这些子结果得到完整的因果网络。CDSC算法相对于其他因果分解方法的显著优势在于其使用简化的谱聚类,以保留子集的连通性,从而避免破坏分隔子集中的因果关系。但CDSC算法也有其缺点:当子集数量较多时,CDSC算法可能表现不佳。因为过多的子集数量可能导致子集内变量个数不足或变量在子集间的重叠度增加,影响精度和效率。
此外,基于评分的因果发现算法[19-22]主要有贪婪等价搜索(Greedy Equivalence Search,GES)算法[19]和快速贪婪等价搜索(Fast Greedy Equivalence Search,FGES)算法[20]等。GES算法利用观测数据在DAG空间中搜索获取真实分布的完备图,但在有限样本的情况下计算复杂度较高。FGES算法是对GES算法的改进,采用启发式方法来减少搜索空间,但牺牲了一定的准确性。Non-combinatorial Optimization via Trace Exponential and Augmented lagRangian for Structure learning(NOTEARS)算法[21]提供了一个新的因果发现视角,主要是将组合约束优化问题转化为实矩阵上纯连续优化问题,然后用数值优化算法进行求解。DAG structure learning with Graph Neural Networks (DAG-GNN)算法[22]结合了深度学习和图神经网络,旨在从数据中学习DAG的结构。DAG-GNN能够捕获复杂的非线性关系,且可以自然地处理离散变量以及向量值变量,但其时间复杂度较高,难以处理高维因果发现问题。
1.2 K-means聚类K-means聚类是一种基于距离度量的聚类算法,旨在将数据集划分为k个不同的簇,以使簇内的数据点尽可能相似,而簇间的数据点尽可能不相似。通过迭代更新簇的中心(质心)和将数据点分配到最近的簇中来优化簇的划分,直到满足停止迭代的条件。作为一种简单而有效的算法,K-means聚类可以将数据点分组成不同的簇,每个簇代表着一组具有相似特征的数据点。从因果发现的角度来看,这些簇可以被解释为潜在的因果成分或因果因素,它们在因果关系中可能起着相似的作用或具有相似的影响。因果分析通常涉及复杂的数据和概念,而K-means聚类的简单性使其成为解释和理解因果关系的理想选择。研究人员和决策者可以轻松理解该算法如何将数据分成不同的组,并且可以直观地解释结果。
K-means聚类首先从n个样本数据中随机选择k个对象作为初始质心,然后分别计算各样本到各质心的距离,将数据分配到距离最近的簇中,接着重新计算每个簇的中心点,并将新计算的质心作为每个簇的新中心点。这个过程不断地重复,直到质心不再改变时,停止并输出聚类结果[23]。K-means聚类是一种广泛应用的无监督学习算法,已被证明在许多领域和应用中都具有良好的效果,如矿产资源勘探[24]、市场细分[25]、矿产远景预测[26]和热环境区域化研究[27]等。由于K-means聚类的稳定性、强泛化性及其优秀的聚类性能,本研究将其应用于因果分解中,为因果分析提供了新的思路和方法。
2 基于K-means聚类的因果分解算法 2.1 CDKM的框架CDKM (图 1)的输入包括原始变量集V、因果发现算法Ag(本研究采用PC算法)和簇的个数k。CDKM首先利用K-means聚类将原始变量集V分割成k个簇

|
| 图 1 CDKM的流程 Fig. 1 Flowchart of CDKM |
2.2 CDKM因果分解策略
在因果分解中,为了避免冗余的条件独立性测试,本研究利用K-means聚类对原始变量集V进行分解。K-means聚类通过计算数据点之间的距离来划分数据集。常用的欧式距离与因果性关系不大,相关性与因果性存在一定的关系,因此,本研究选用相关距离[式(1)]进行聚类。
| $ d\left(v_i, v_j\right)=1-\frac{\operatorname{cov}\left(v_i, v_j\right)}{\sqrt{\operatorname{cov}\left(v_i, v_i\right) \operatorname{cov}\left(v_j, v_j\right)}}, $ | (1) |
其中,vi,vj是两个变量,cov(vi,vj)表示vi和vj的协方差,cov(vi,vi)为vi的方差,cov(vj,vj)为vj的方差。
CDKM的分解过程如算法1所示。
算法1 CDKM因果分解策略
输入: 原始变量集V,簇的个数k,增加的节点数q
输出: k个簇
1. 初始化:
2. 对
3. Repeat
4. 对
5. If
6. 将vj添加到Vi中
7. End if
8. 计算新的聚类中心
9. If ci′≠ci then
10. 令ci=ci′
11. End if
12. until ci=ci′
13. 对
14. 令
15. 在di中找到前q个最小值,令
| $ \begin{aligned} & d_i^{\min }=\left(d_i\left(v_{i j_1^{\prime}}, v_{j_1^{\prime}}^{\prime}\right), d_i\left(v_{i j_2^{\prime}}, v_{j_2^{\prime}}\right), \cdots, d_i\left(v_{i j_q^{\prime}}, \right.\right. \\ & \left.\left.v_{j_q^{\prime}}^{\prime}\right)\right)^{\mathrm{T}} \end{aligned} $ |
16. 将节点vj1′,vj2′,…,vjq′添加到Vi
17. Return更新后的k个簇
对原始变量集V进行因果分解后,CDKM选用指定的因果发现算法Ag在每个簇Vi上进行因果发现,得到各个簇对应的子因果网络
由于K-means聚类划分的簇之间不存在交集,无法发现不同簇节点间的因果关系,即无法建立子因果网络之间的因果关系;故在CDKM的分解部分中,在进行K-means聚类后,本研究为每个簇添加了其他簇中与其相关距离最小的q个节点,保证了不同簇之间存在重叠部分,使因果发现算法Ag能够恢复不同簇之间的因果关系。根据文献[18],取q=2,这既可以防止簇中节点数目不足,导致在其上难以进行因果发现,也可以避免簇中节点数目过多进而影响算法的效率。
针对每个簇的因果发现和合并子因果网络的问题,本研究不失一般性地选用PC算法来作为因果发现算法。CDKM在确定因果方向时有两种操作:一是通过条件独立性测试检测到的对撞结构来确定因果方向;二是因条件独立性测试无法区分Markov等价类,即无法区分v1→v2→v3、v1←v2←v3和v1←v2→v3,故在区分Markov等价类时,通过检验独立变量z是否独立于残差v1-E(v1|Z)和v3-E(v3|Z)来确定因果方向。
子因果网络之间存在重叠部分,使得它们之间可能会发生一些冲突,尤其是在处理含有大量变量的数据集时。在实践中,可能出现在Gi和Gj中分别推断出不同的因果方向的冲突。比如在Gi中的因果方向是vi→vj,而在Gj中的因果方向是vi←vj。一般而言,这种冲突取决于DAG对因果网络的假设[20]。针对这类冲突,CDKM首先用两个变量的(条件)独立性测试计算出相应的显著性数值(简称SV),然后选择SV较高的边作为最终结果。比如,若满足SVvi→vj=P((vi-E(vi|Z))
总的来说,CDKM的合并操作可以归结为4步:首先,根据原始变量集V构建无边图G′;其次,将各Gi的因果边都添加到G′中;接着,对于G′出现的冲突因果边,删除SV更低的因果边,并更新G′;最后,令G=G′,从而得到完整因果网络G。算法2为CDKM合并子因果网络的伪代码。
算法2 合并子因果网络
输入: 原始变量集V,子因果网络
输出: 完整因果网络G
1. 根据V构建无边图G′。
2. 对
3. 若vi→vj和vi←vj同时存在G′中,且SVvi→vj≥SVvi←vj,则删除vi←vj,否则删除vi→vj,更新G′。
4. 令G=G′,从而得到完整因果网络G。
2.4 时间复杂度条件独立性测试占据了因果发现算法95%以上的时间[8]。因此,CDKM的时间复杂度主要由K-means聚类和在簇内进行因果发现的时间复杂度组成。
命题1 令原始变量集V={v1,v2,…,vn},CDKM将V划分为k个簇{Vi}i=1k,其中每个簇的大小为|Vi|,设:pmax=max(|V1|,|V2|,…,|Vk|),d为变量的维度,t为K-means聚类的迭代次数,m为条件独立性测试的时间复杂度,已知K-means聚类的时间复杂度为Ο(kndt),PC算法的时间复杂度为Ο(mn22n-2),若CDKM在每个簇内使用PC算法进行因果发现,则当n较大时,CDKM的时间复杂度为
证明 因为CDKM在每个簇内使用PC算法进行因果发现,所以CDKM在每个簇上进行因果发现的时间复杂度为
命题1说明了在高维情形下,CDKM相比于PC算法具有更低的时间复杂度,因果发现的速度更快,因此具有可行性。
3 实验与结果分析为了验证和分析本研究提出的算法的有效性,本研究在8个现实因果网络上做了算法性能评估和对比实验。具体来说,一是使用不同数量的簇个数k对这8个数据集评价此算法的性能;二是本研究将CDKM与CDSC[18]、PC[8]、SADA[16]这3个性能优越的因果发现算法进行比较,其中和PC算法的对比是关于CDKM分解操作的消融实验。
3.1 实验设置实验的软件环境为Windows 11操作系统和Matlab2022a,硬件环境配备AMD Ryzen 5 5600H with Radeon Graphics处理器与16 GB内存。参数实验和对比实验均设置每个数据的样本容量为600,每个实验运行25次,取25次实验的平均值作为最终结果。
3.1.1 数据集在这组实验中,本研究选用Sachs、Water、Insurance、Alarm、Barley、Hailfinder、Win95pts和Andes这8个现实世界的因果网络进行实验。表 1给出了这些因果网络的具体信息。它们涵盖了生物信息学(Sachs)、保险评估(Insurance)、环境保护(Water)、医学(Alarm)、农业(Barley)、天气预报(Hailfinder)和系统故障排障(Win95pts、Andes)等方面的应用。
| 数据集 Dataset |
节点数 Number of nodes |
平均入度 Average in-degree |
最大入度 Maximum in-degree |
| Sachs | 11 | 3.09 | 7 |
| Insurance | 27 | 3.95 | 9 |
| Water | 32 | 4.13 | 8 |
| Alarm | 37 | 4.49 | 6 |
| Barley | 48 | 2.49 | 8 |
| Hailfinder | 56 | 2.36 | 17 |
| Win95pts | 76 | 1.84 | 9 |
| Andes | 223 | 3.03 | 12 |
因为这些原始变量集是因果网络而不是具体的数据,故在进行分解之前,需先将因果网络生成数据。因为在现实世界中大规模的具有真值的因果发现问题不常见,而大多数的真实数据满足ANM[28]:
| $ v_i=\sum\limits_{v_j \in P a\left(v_i\right)} \omega_{i j} v_j+\varepsilon_i, $ | (2) |
其中,Pa(vi)为vi的父节点集合,εi为非高斯噪声项,ωij是父节点vj对vi的权重,生成数据的过程满足ωijPa(vi)=1,var(εi)=1;故本研究选用ANM生成数据,数据生成过程参考文献[16]。
3.1.2 评估指标本研究选用召回率(R)、精准率(P)和F1分数(F1)这3个指标评估CDKM的准确性,选用运行时间来评估算法的效率。
召回率衡量的是在实际存在因果关系的样本中,算法正确识别出存在因果关系的样本所占的比例,即
| $ R=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}, $ | (3) |
其中,TP (True Positives)为识别出存在因果关系且实际也存在因果关系的样本数,FN (False Negative)为识别出不存在在因果关系但实际存在因果关系的样本数。
精准率衡量的是在算法识别为存在因果关系的样本中,实际存在因果关系的样本所占的比例,即
| $ P=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}, $ | (4) |
其中,FP (False Positive)为识别出存在因果关系但实际不存在因果关系的样本数,F1分数是召回率和精准率的调和平均数,旨在综合考虑二者性能,使两者同时达到较高水平。其公式如下:
| $ F 1=\frac{2 \times R \times P}{R+P} 。$ | (5) |
本节研究簇个数k对CDKM准确性和效率的影响,以及找到使得CDKM在各个数据集上表现最佳的k值。在这组实验中,设置k={2,3,…,8}。需要注意的是CDKM在Sachs和Insurance上的值不能设置太大,因为随着k值的增大,簇变得越来越相似,不同簇中的许多节点变得相同。
图 2说明了簇个数k对CDKM算法准确性的影响。CDKM在每个数据集上的召回率随着k值的增加而增大,即CDKM成功发现因果关系的比例在增大。相反,精准率随着k值的增大而减小,说明CDKM正确发现因果关系的可靠性在降低。这可能是当划分的簇个数过多时,簇内变量较少,可供参考的背景信息减少,从而增加了因果推断错误的风险。此外,CDKM在Sachs、Insurance、Hailfinder、Win95pts和Andes上的F1分数随着k值的增大而减小。这说明随着k值的增加,CDKM在因果发现任务中准确识别真实因果关系和避免错误推断的能力逐渐下降,导致其在整体因果发现效果上表现不佳。而CDKM在Water、Alarm和Barley上随着k值的增大F1分数表现出先升高后降低的趋势。这表明在这些数据集上,存在一个较优的簇个数范围,使得CDKM具备更强的能力去精准识别出数据中的因果关系,尽可能减少误判和漏判。不过,一旦簇个数超出这个范围,CDKM在因果发现任务中准确挖掘因果关联、有效区分真实因果与虚假关联的能力就会减弱,进而导致算法整体性能下滑。

|
| 图 2 不同簇数k下CDKM的性能评估 Fig. 2 CDKM performance evaluation under different cluster numbers k |
根据图 3,CDKM对Sachs、Insurance、Water、Alarm、Barley、Hailfinder、Win95pts和Andes这8个数据集的效率通常随着k值的增大而提高,这说明划分的簇个数越多,越能提升CDKM的效率,因为这样能够减少CDKM原本要执行的冗余条件独立性测试。

|
| 图 3 不同簇数k下CDKM的运行时间 Fig. 3 CDKM running time under different cluster numbers k |
基于图 2和图 3,本研究总结了CDKM在Sachs、Insurance、Water、Alarm、Barley、Hailfinder、Win95pts和Andes这8个数据集上表现最佳的k值(表 2)。
| 数据集 Dataset |
最优k值 The optimal k value |
| Sachs | 2 |
| Insurance | 2 |
| Water | 5 |
| Alarm | 5 |
| Barley | 6 |
| Hailfinder | 2 |
| Win95pts | 2 |
| Andes | 2 |
最佳簇个数的选择通常要在准确性和效率之间进行权衡,当前最先进的递归方法在效率方面表现出色,但本研究更倾向于准确性而不是效率,特别考虑到算法的可接受性。由表 2可知,划分数据集的最优k值大多等于2。这表明划分的簇个数过多可能导致簇无法保持稀疏性,从而影响CDKM的准确性。因此,本研究更注重保持因果网络的准确性而不过度追求簇的数量,以确保结果的可靠性。
综上,不同的簇个数k会对CDKM的性能产生影响,且随着k值的增加,CDKM在每个因果网络上的召回率变大,精准率变小,运行时间变短,CDKM在Insurance、Hailfinder、Win95pts和Andes上的F1分数减小,而在Sachs、Water、Alarm和Barley这4个数据集上先变大后减小。这是因为随着划分簇个数的增加,使用条件独立性测试的次数减少,从而使CDKM的速度加快。
3.3 对比实验本节将CDKM与SADA、PC、CDSC这3个性能优越的因果发现算法进行比较,主要比较这些算法在Sachs、Insurance、Water、Alarm、Barley、Hailfinder、Win95pts和Andes这8个数据集的召回率、精准率、F1分数和运行时间上的差异。CDKM的k值选用表 2中的最优k值。对比实验结果如表 3所示,其中召回率、精准率、F1分数以“平均值±标准差”的形式给出。
| 数据集 Dataset |
算法 Algorithm |
召回率 Recall |
精准率 Precision |
F1分数 F1 score |
运行时间/s Running time/s |
| Sachs | CDKM | 0.957 1±0.003 7 | 0.968 9±0.004 6 | 0.960 8±0.002 1 | 0.05 |
| CDSC | 0.957 1±0.003 7 | 0.968 9±0.004 6 | 0.960 8±0.002 1 | 0.05 | |
| PC | 0.962 0±0.002 4 | 0.987 0±0.005 9 | 0.973 9±0.007 9 | 31.07 | |
| SADA | 0.001 2±0.003 7 | 0.001 2±0.002 3 | 0.001 1±0.002 7 | 0.07 | |
| Insurance | CDKM | 0.888 4±0.003 6 | 0.972 1±0.004 6 | 0.928 4±0.017 9 | 5.88 |
| CDSC | 0.804 1±0.005 4 | 0.847 9±0.004 2 | 0.827 4±0.015 3 | 1.76 | |
| PC | 0.883 2±0.004 2 | 0.992 6±0.003 6 | 0.924 1±0.004 3 | 613.01 | |
| SADA | 0.024 8±0.018 7 | 0.019 7±0.016 6 | 0.026 2±0.020 0 | 0.16 | |
| Water | CDKM | 0.556 8 ±0.010 4 | 0.930 5±0.013 3 | 0.694 1±0.014 0 | 0.34 |
| CDSC | 0.499 7±0.007 6 | 0.879 6±0.020 5 | 0.643 7±0.012 9 | 0.73 | |
| PC | 0.571 0±0.010 9 | 0.958 1±0.004 1 | 0.718 6±0.010 4 | 574.19 | |
| SADA | 0.062 1±0.008 1 | 0.046 7±0.098 1 | 0.053 5±0.007 5 | 0.51 | |
| Alarm | CDKM | 0.608 0±0.022 4 | 0.838 6±0.009 5 | 0.701 5±0.017 9 | 0.15 |
| CDSC | 0.592 4±0.020 4 | 0.780 4±0.035 6 | 0.667 3±0.014 8 | 0.19 | |
| PC | 0.777 2±0.005 5 | 0.981 9±0.013 0 | 0.855 3±0.013 1 | 938.81 | |
| SADA | 0.319 3±0.017 7 | 0.220 3±0.015 3 | 0.261 0±0.019 4 | 1.68 | |
| Barley | CDKM | 0.493 0±0.010 1 | 0.648 6±0.016 0 | 0.561 5±0.013 2 | 1.32 |
| CDSC | 0.461 7±0.004 9 | 0.588 5±0.011 6 | 0.508 7±0.004 7 | 0.96 | |
| PC | 0.609 1±0.004 5 | 0.987 1±0.008 5 | 0.753 0±0.006 2 | 2 881.80 | |
| SADA | 0.235 9±0.012 7 | 0.016 9±0.010 1 | 0.202 0±0.011 3 | 1.39 | |
| Hailfinder | CDKM | 0.791 4±0.003 4 | 0.841 7±0.011 8 | 0.814 8±0.003 6 | 10.03 |
| CDSC | 0.782 2±0.004 7 | 0.838 4±0.007 9 | 0.808 7±0.002 3 | 10.58 | |
| PC | 0.861 1±0.006 7 | 0.925 4±0.014 2 | 0.886 4±0.004 1 | 2 456.10 | |
| SADA | 0.344 7±0.005 7 | 0.226 0±0.007 4 | 0.273 6±0.008 3 | 1.76 | |
| Win95pts | CDKM | 0.683 0±0.021 0 | 0.748 6±0.025 3 | 0.712 1±0.027 7 | 66.61 |
| CDSC | 0.814 6±0.002 2 | 0.840 9±0.007 1 | 0.825 3±0.003 2 | 61.89 | |
| PC | 0.886 4±0.006 7 | 0.887 1±0.014 5 | 0.872 1±0.010 5 | 27 176.00 | |
| SADA | 0.319 1±0.013 4 | 0.279 5±0.018 3 | 0.301 9±0.017 6 | 72.91 | |
| Andes | CDKM | 0.717 3±0.000 0 | 0.818 3±0.000 0 | 0.763 9±0.000 0 | 4 673.30 |
| CDSC | 0.798 6±0.000 0 | 0.926 6±0.000 0 | 0.857 8±0.000 0 | 4 826.50 | |
| PC | 0.889 6±0.000 0 | 0.979 9±0.000 0 | 0.921 6±0.000 0 | 68 556.00 | |
| SADA | 0.359 7±0.000 0 | 0.130 7±0.000 0 | 0.187 0±0.000 0 | 38 822.00 | |
| Note: data in bold are the optimal results, and data underlined are the second-best results of the comparison experiment. | |||||
由表 3可以看出,在召回率方面,CDKM在Insurance数据集上表现优于其他3个算法,而在Sachs、Water、Alarm、Barley和Hailfinder数据集上略逊于PC算法。这表明CDKM在正确识别因果边上的能力仅次于PC算法,这是因为CDKM没有遍历式地对观测变量进行条件独立性测试,而PC算法采用了全局遍历条件独立性测试。CDKM在整体上略优于CDSC算法,这是因为K-means聚类在效果上较谱聚类更为出色,簇的划分更为合理,从而提高了正确识别因果关系的数量。相比之下,SADA在召回率上表现不佳,可能是由于在进行分割时切割点选择不当,破坏了图的连通性,导致一些因果关系被忽略。
从精准率来看,PC算法在这8个数据集上均表现出最优性能,CDKM整体上表现为次优。由于条件独立性测试具有较高的准确性,PC算法在精准率方面表现尤为突出。CDKM低于PC算法,可能是因为对数据进行划分后,簇内变量较少,可供参考的背景信息减少,从而增加了因果推断错误的风险。CDSC算法相较于CDKM略差,可能是由于其簇划分质量稍逊,导致条件独立性测试可能标记不正确的因果关系。而SADA在精准率上不足,可能是因为其对稀疏性约束的假设限制了其捕获复杂因果关系的能力。
最后,在综合考虑召回率和精准率的F1分数上,PC算法在Sachs、Water、Alarm、Barley、Hailfinder、Win95pts和Andes这7个数据集上均表现最优,证明了其在综合性能上的优势性。而在Insurance上,CDKM取得了最优表现。尽管CDKM在F1分数上略逊于PC算法,但其在与CDSC算法和SADA的比较中仍表现较好,这证明了CDKM在识别因果关系方面具有一定的准确性。CDKM在F1分数上的不足,可能源于其分割策略导致不同簇节点间的因果关系被遗漏或因果方向判断错误。
在Alarm和Andes上运行时间最少的是CDKM,在Barley和Win95pts上运行时间最少的是CDSC算法,在Insurance和Hailfinder上运行时间最少的是SADA,整体上看CDKM、CDSC算法和SADA的运行时间较少,而PC算法的运行时间高出很多,这是因为PC算法需遍历式地对观测变量进行条件独立性测试来找到所有条件集,故消耗时间多。SADA在Andes上的运行时间剧增,是因为随着数据维度的增加,用于分解的高阶条件独立性测试会大大增加SADA的运行时间。CDKM在高维上具有良好的时间表现,是因为K-means聚类在最佳簇个数k下划分子集,避免了分解时进行高阶条件独立性测试,大大提高了时间效率。
为了检验CDKM和PC算法在各数据集上的召回率、精准率和F1分数有无显著性差异,利用配对样本Wilcoxon符号秩检验进行检验,假设CDKM和PC算法在各数据集上的召回率、精准率和F1分数没有显著性差异,检验结果如表 4所示。
| 数据集 Dataset |
P值 Pvalue |
| Sachs | 0.25 |
| Insurance | 1.00 |
| Water | 0.25 |
| Alarm | 0.25 |
| Barley | 0.25 |
| Hailfinder | 0.25 |
| Win95pts | 0.25 |
| Andes | 0.25 |
从表 4可以看出,计算出的P值均大于0.05,故在5%的显著性水平下无法拒绝原假设,证明CDKM和PC算法在各数据集上的召回率、精准率和F1分数没有显著性差异,表明CDKM能够保证准确性。尽管CDKM的召回率、精准率和F1分数低于PC算法,但不存在显著性差异,且CDKM的时间效率远高于PC算法,说明CDKM的方法是有效的。
4 结论本研究将K-means聚类方法与条件独立性测试结合,提出了一种基于K-means聚类的因果分解方法CDKM。CDKM通过K-means聚类将原始因果发现问题划分为多个子因果发现问题,避免了高阶条件独立性测试,并减少了冗余测试。相比递归型基于约束的方法,CDKM能够根据需求灵活分割变量集。在8个现实数据集上的实验结果表明,CDKM可以极大地加速因果发现,降低时间复杂度,且精准度优于基线模型。
然而,CDKM也有其不足之处。CDKM利用K-means聚类对原始变量集进行分割,破坏了因果充分性,无法正确地识别出关键原因变量,从而导致精准率下降。此外,K-means对初始聚类中心的选择敏感,不同的初始中心会导致不同的聚类结果,聚类结果不稳定,可能会导致因果发现结果的不确定性,或者对数据中隐藏的因果关系产生误导。
未来,将聚类方法与条件独立性测试相结合,深入探究因果分割技术,有望解决因果分解领域固有的局限。通过改进初始聚类中心的选择,如采用K-means++方法[29],可以让聚类结果更具稳定性,但如何让划分子集保留完整的局部因果关系是一项艰巨的挑战。同时,针对缺失、嘈杂和动态的现实世界的数据,提出适用的因果发现方法至关重要,这是未来的研究重点之一。
| [1] |
KALYAN K S. A survey of GPT-3 family large language models including ChatGPT and GPT-4[J]. Natural Language Processing Journal, 2024, 6: 100048. DOI:10.1016/j.nlp.2023.100048 |
| [2] |
KUMAR P. Large language models (LLMs): survey, technical frameworks, and future challenges[J]. Artificial Intelligence Review, 2024, 57(10): 260. DOI:10.1007/s10462-024-10888-y |
| [3] |
TEIXEIRA-MARQUES F, MEDEIROS N, NAZARÉ F, et al. Exploring the role of ChatGPT in clinical decision-making in otorhinolaryngology: a ChatGPT designed study[J]. European Archives of Oto-Rhino-Laryngology, 2024, 281(4): 2023-2030. DOI:10.1007/s00405-024-08498-z |
| [4] |
SHEN S A, PEREZ-HEYDRICH C A, XIE D X, et al. ChatGPT vs.web search for patient questions: what does ChatGPT do better?[J]. European Archives of Oto-Rhino-Laryngology, 2024, 281(6): 3219-3225. DOI:10.1007/s00405-024-08524-0 |
| [5] |
CHEN H L, JIAO F K, LI X X, et al. ChatGPT's one-year anniversary: are open-source large language models catching up?[EB/OL]. (2024-01-15)[2024-04-22]. https://arxiv.org/abs/2311.16989v4.
|
| [6] |
MILLER T. Explanation in artificial intelligence: insights from the social sciences[J]. Artificial Intelligence, 2019, 267: 1-38. DOI:10.1016/j.artint.2018.07.007 |
| [7] |
杨俊闯, 赵超. K-means聚类算法研究综述[J]. 计算机工程与应用, 2019, 55(23): 7-14, 63. |
| [8] |
SPIRTES P, GLYMOUR C. An algorithm for fast recovery of sparse causal graphs[J]. Social Science Computer Review, 1991, 9(1): 62-72. DOI:10.1177/089443939100900106 |
| [9] |
VERMA T, PEARL J, VERMA T, et al. Equivalence and synthesis of causal models[C]//Proceedings of the 6th Annual Conference on Uncertainty in Artificial Intelligence. New York: ACM, 1990: 255-270.
|
| [10] |
YAO L Y, CHU Z X, LI S, et al. A survey on causal inference[J]. ACM Transactions on Knowledge Discovery from Data, 2021, 15(5): 1-46. |
| [11] |
SPIRTES P, MEEK C, RICHARDSON T. Causal inference in the presence of latent variables and selection bias[EB/OL]. (2013-02-20)[2024-04-22]. https://arxiv.org/abs/1302.4983.
|
| [12] |
SHIMIZU S, HOYER P O, HYVÄRINEN A, et al. A linear non-Gaussian acyclic model for causal discovery[J]. Journal of Machine Learning Research, 2006, 7: 2003-2030. |
| [13] |
SHIMIZU S, INAZUMI T, SOGAWA Y, et al. DirectLiNGAM: a direct method for learning a linear non-Gaussian structural equation model[J]. Journal of Machine Learning Research, 2011, 12: 1225-1248. |
| [14] |
HOYER P O, JANZING D, MOOIJ J M, et al. Nonlinear causal discovery with additive noise models[C]//Proceedings of the 22nd International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2008: 689-696.
|
| [15] |
ZHANG K, HYVÄRINEN A. On the identifiability of the post-nonlinear causal model[EB/OL]. (2012-05-09)[2024-04-22]. https://arxiv.org/abs/1205.2599.
|
| [16] |
CAI R C, ZHANG Z J, HAO Z F. SADA: a general framework to support robust causation discovery[C]//Proceedings of the 30th International Conference on Machine Learning. New York: ACM, 2013: 208-216.
|
| [17] |
ZHANG H, ZHOU S G, YAN C X, et al. Learning causal structures based on divide and conquer[J]. IEEE Transactions on Cybernetics, 2020, 52(5): 3232-3243. |
| [18] |
CHEN S F, PENG Y Z, HE G Y, et al. CDSC: causal decomposition based on spectral clustering[J]. Information Sciences, 2024, 657: 119985. DOI:10.1016/j.ins.2023.119985 |
| [19] |
CHICKERING D M. Optimal structure identification with greedy search[J]. Journal of Machine Learning Research, 2003, 3: 507-554. |
| [20] |
RAMSEY J. Scaling up greedy causal search for continuous variables[EB/OL]. (2015-11-11)[2024-04-22]. https://arxiv.org/abs/1507.07749.
|
| [21] |
ZHENG X, ARAGAM B, RAVIKUMAR P, et al. DAGs with NO TEARS: continuous optimization for structure learning[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2018: 9492-9503.
|
| [22] |
YU Y, CHEN J, GAO T, et al. DAG-GNN: DAG structure learning with graph neural networks[C]//Proceeding of the 36th International Conference on Machine Learning. Long Beach: PMLR, 2019: 7154-7163.
|
| [23] |
LIU H F, CHEN J X, DY J, et al. Transforming complex problems into K-means solutions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(7): 9149-9168. |
| [24] |
GHEZELBASH R, DAVIRAN M, MAGHSOUDI A, et al. Incorporating the genetic and firefly optimization algorithms into K-means clustering method for detection of porphyry and skarn Cu-related geochemical footprints in Baft district, Kerman, Iran[J]. Applied Geochemistry, 2023, 148: 105538. DOI:10.1016/j.apgeochem.2022.105538 |
| [25] |
HANJI S, HANJI S. Towards performance overview of mini batch K-means and K-means: case of four-wheeler market segmentation[C]//Smart Trends in Computing and Communications. Singapore: Springer Nature Singapore, 2023: 801-813.
|
| [26] |
GHEZELBASH R, MAGHSOUDI A, SHAMEKHI M, et al. Genetic algorithm to optimize the SVM and K-means algorithms for mapping of mineral prospectivity[J]. Neural Computing and Applications, 2023, 35(1): 719-733. |
| [27] |
KIM Y, KIM Y. Global regionalization of heat environment quality perception based on K-means clustering and Google trends data[J]. Sustainable Cities and Society, 2023, 96: 104710. |
| [28] |
PETERS J, JANZING D, SCHÖLKOPF B. Identifying cause and effect on discrete data using additive noise models[C]//Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Chia Laguna Resort: PMLR, 2010: 597-604.
|
| [29] |
ARTHUR D. K-means++: the advantages of careful seeding[C]//Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. New York: ACM, 2007: 1027-1035.
|